The “interpolation” displays the component’s hero.name property value within the
tags
The [hero] property binding passes the selectedHero from the parent HeroListComponent to the hero property of the child HeroDetailComponent
The (click) event binding calls the Component’s selectHero method when the user clicks on a hero’s name
Two way data binding combines property and event binding in a single notation using ngModel directive
Directive
Class with directive metadata. Even Components are directives - directive with templates.
Two other examples are:
Structural: They alter layout by adding, removing, and replacing elements in DOM
Attributes: Attribute directives alter the appearance or behavior of an existing element. In templates they look like regular HTML attributes, hence the name
Example:
The ngModel directive, which implements two-way data binding, is an example of an attribute directive.
<input[(ngModel)]="hero.name">
Other examples: ngSwitch, ngStyle, ngClass
Service
It can be any value, function or feature that works well.
Dependency Injection
A way to supply a new class instance with all the requirements. In TypeScript this can be achieved by providing everything inside the constructor.
An Injector maintains a list of service instances it has created previously so that it can reuse those if needed. The way it achieves this is by utilizing provider which is used within each Component.
I recently needed to call a command whenever there was a push on my Github repo.
Since this was related to AWS tasks, I figured aws lambda is a good candidate.
Here I will talk about the steps I took to enable all of this using aws lambda, python.
As a side note, I will also elaborate on using API gateway to call upon the lambda itself.
In a nutshell, what I will talk about:
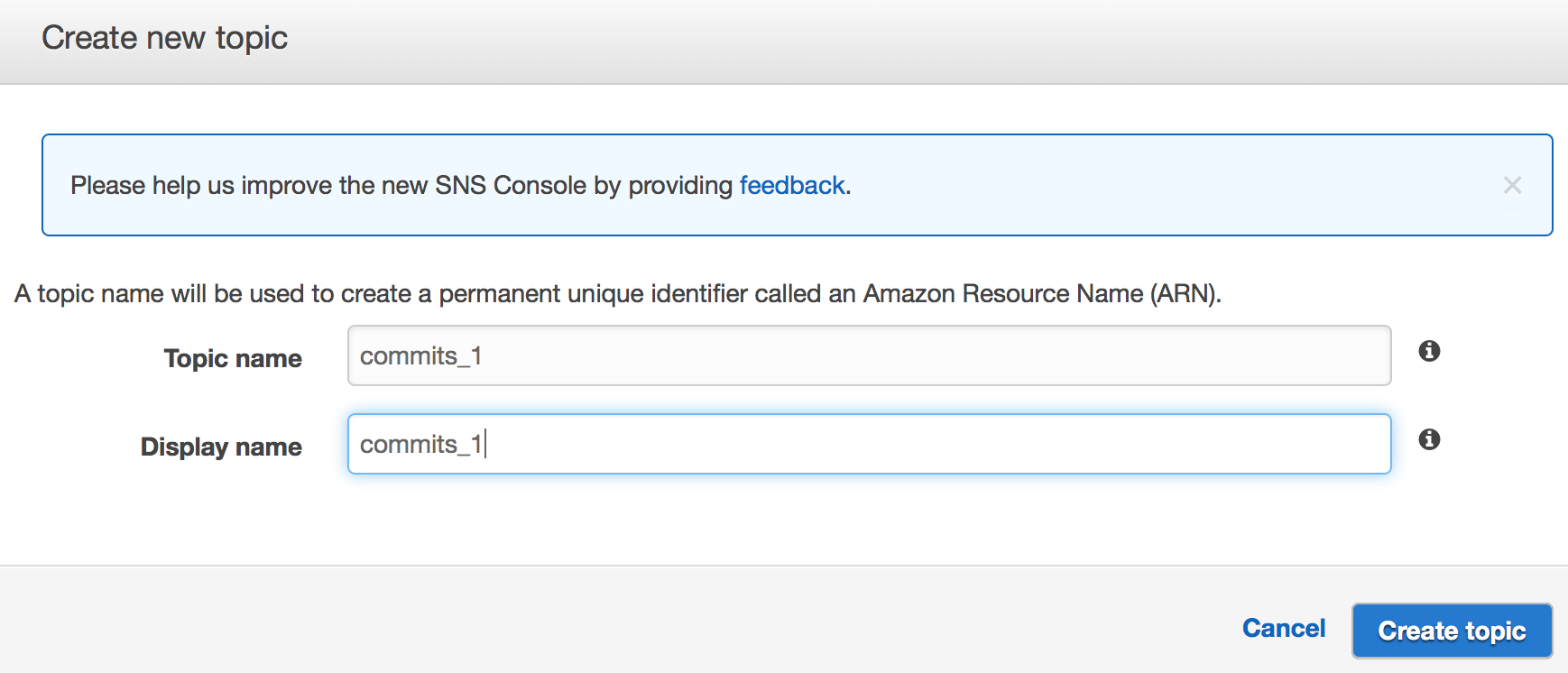
Create SNS Topic
Create IAM user who can Publish
Setup GitHub webhook
Create Lambda function
Setup API Gateway url that can call lambda function
Note down the ARN because you will need that.
In my case it is something like arn:aws:sns:ap-northeast-1:XXXXXXXXXXXX:commits_1
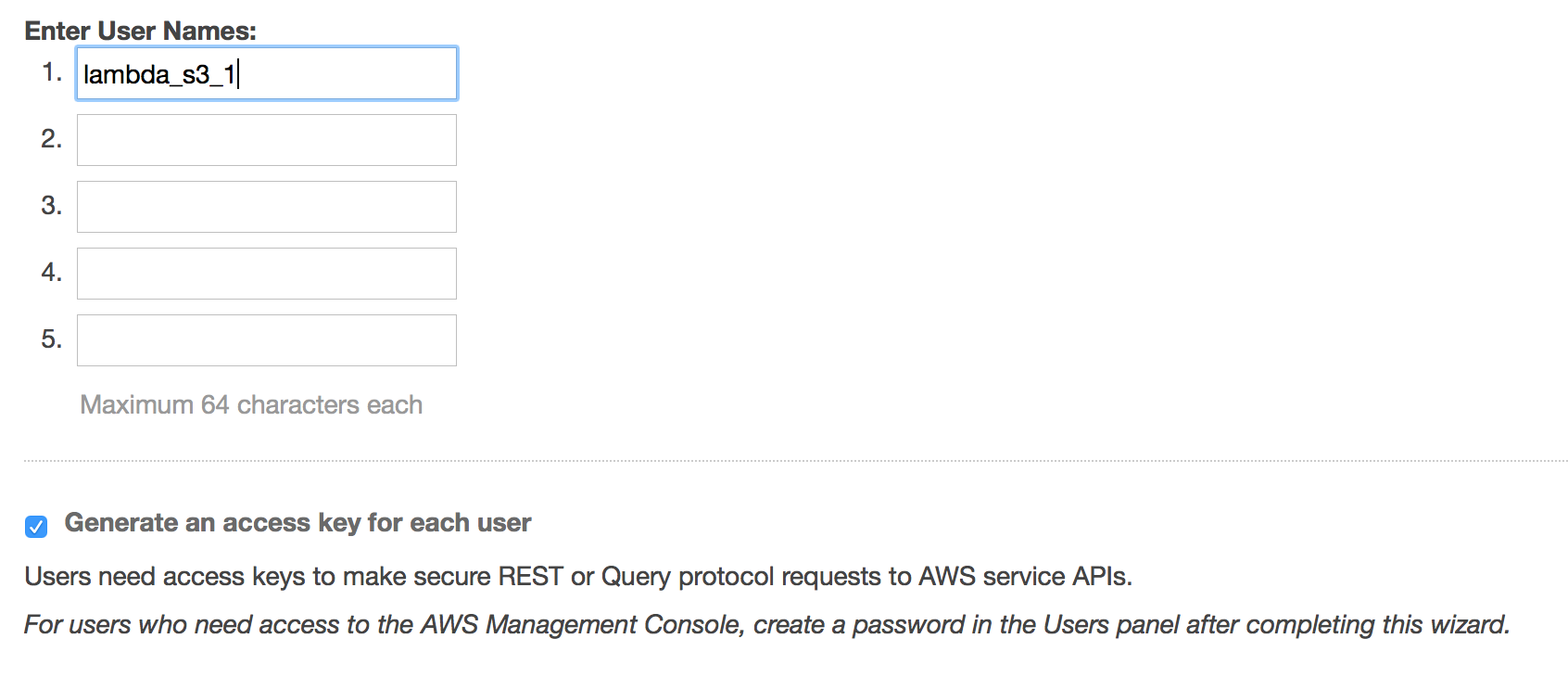
Create IAM user
We need to setup an IAM user who can publish onto this SNS we just created.
As a shortcut you can just create a simple user and initialize it with full access rights for testing purposes.
Once on IAM page click on “Create New Users” button at the top.
Creating new IAM user
It will then allow you to download credentials if you want
Creating new IAM user
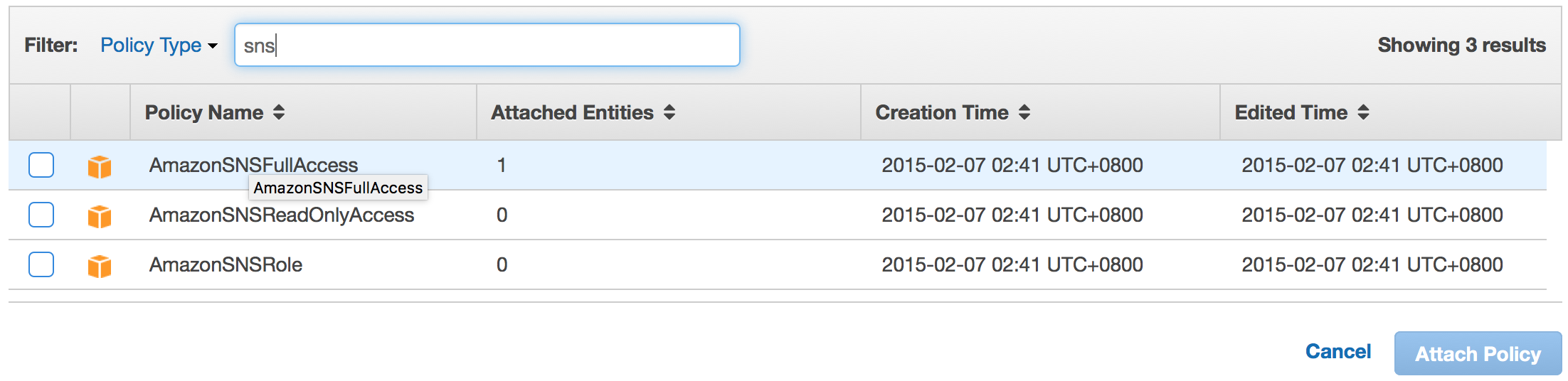
Add permissions
Once an IAM user is created, by default there are no permissions attached to the account.
You can add permissions by going to permissions tab and clicking on “Attach Policy” button.
Attach Policy
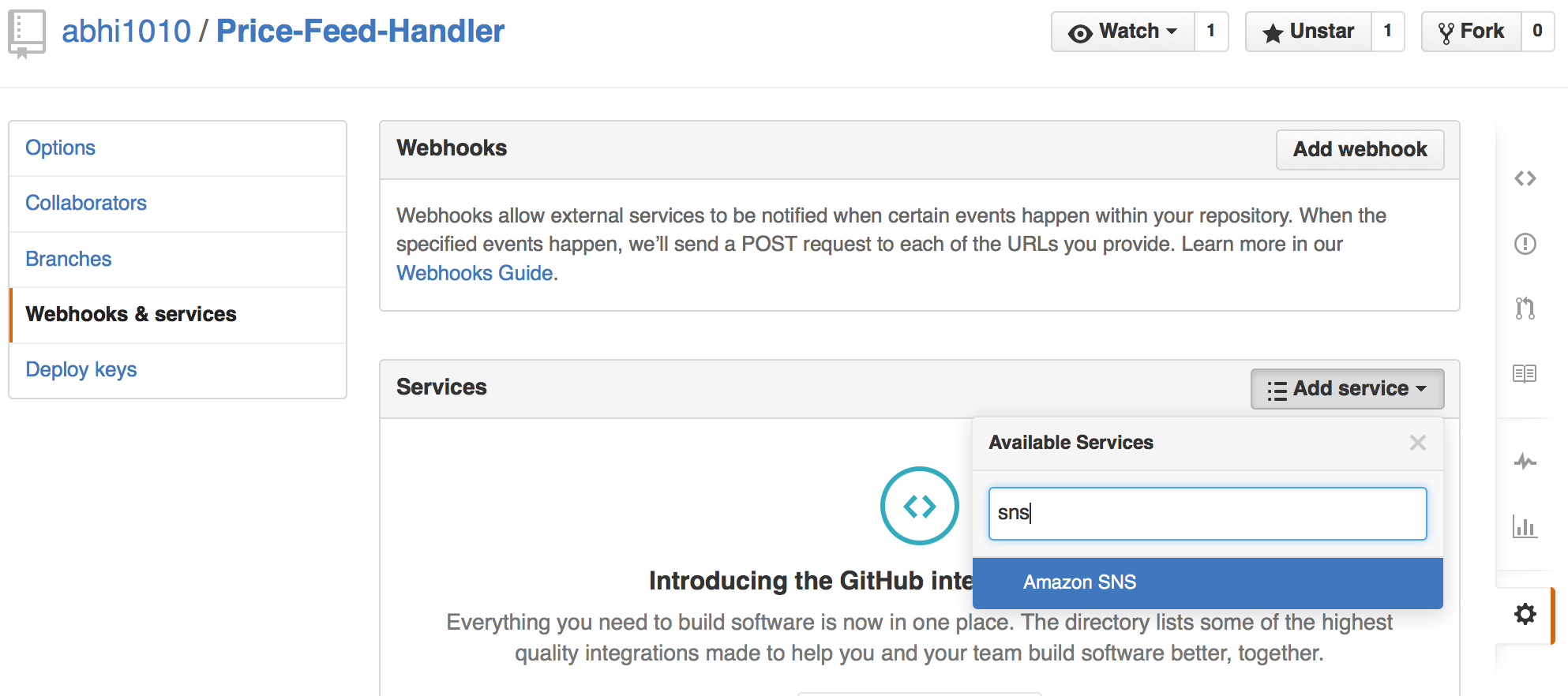
Setup GitHub webhook
We need to assign a webhook for each Git commit. So let’s do the following:
Navigate to your GitHub repo
Click on “Settings” in the sidebar of that repo
It has to be an actual repo settings, not profile settings
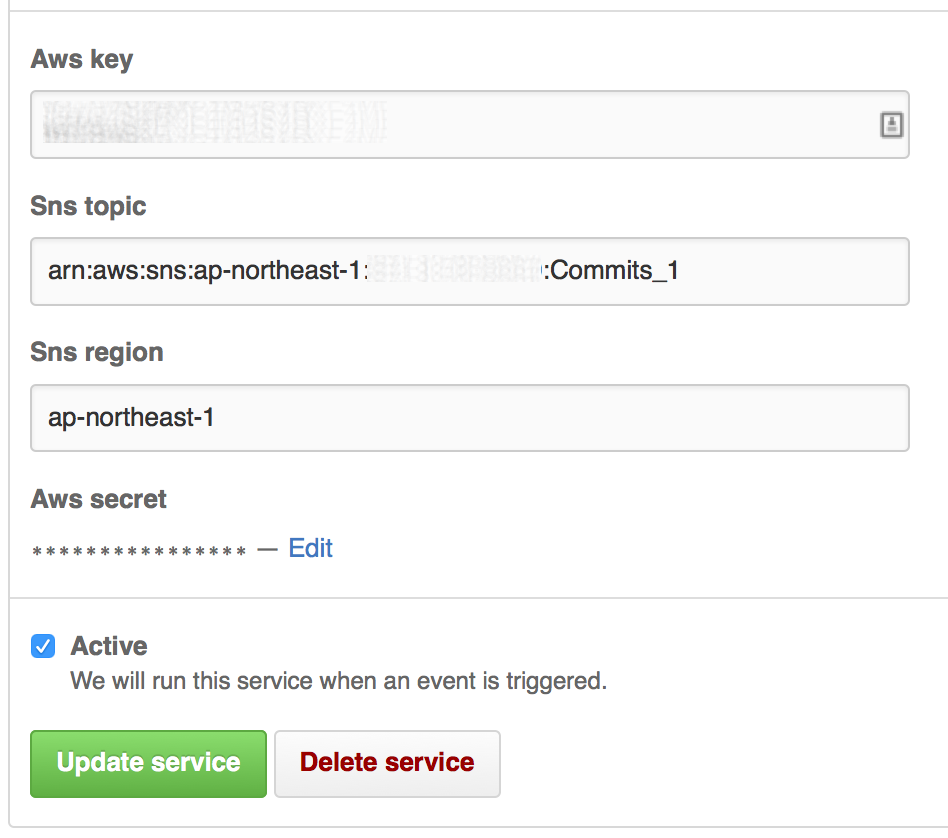
Click on “Webhooks & Services”
Click the “Add service” dropdown, then click “AmazonSNS”
You will need the account details for the IAM user you just created
The trigger will be delegated through this given IAM user
Add SNS Webhook
Add Account details from IAM user
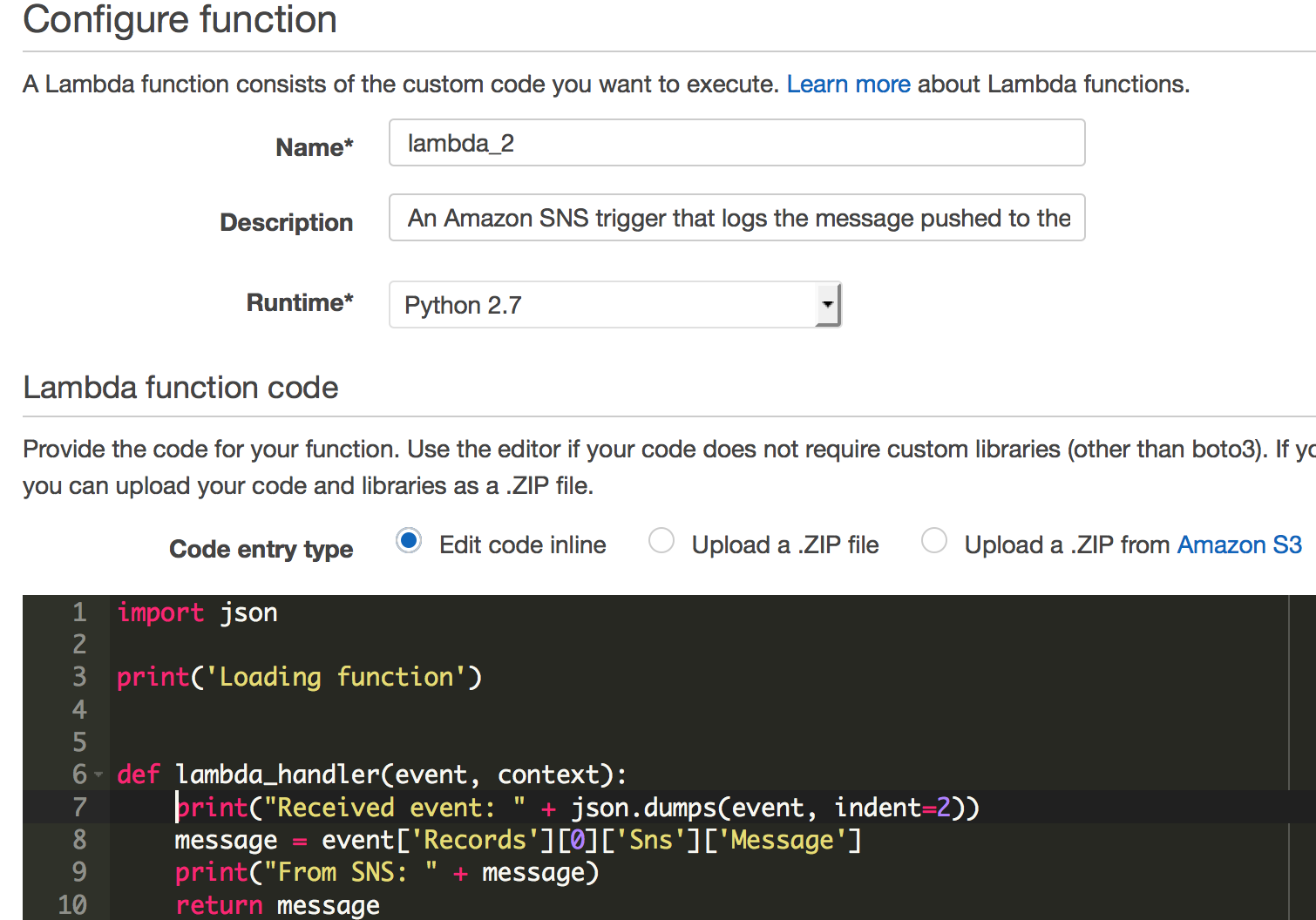
Create Lambda function
Now that we have creater a user, assigned a trigger on Github, we need to create a function
that will be run on an actual trigger.
Let’s create a lambda function by going to AWS Lambda and
clicking on “Create a Lambda Function”.
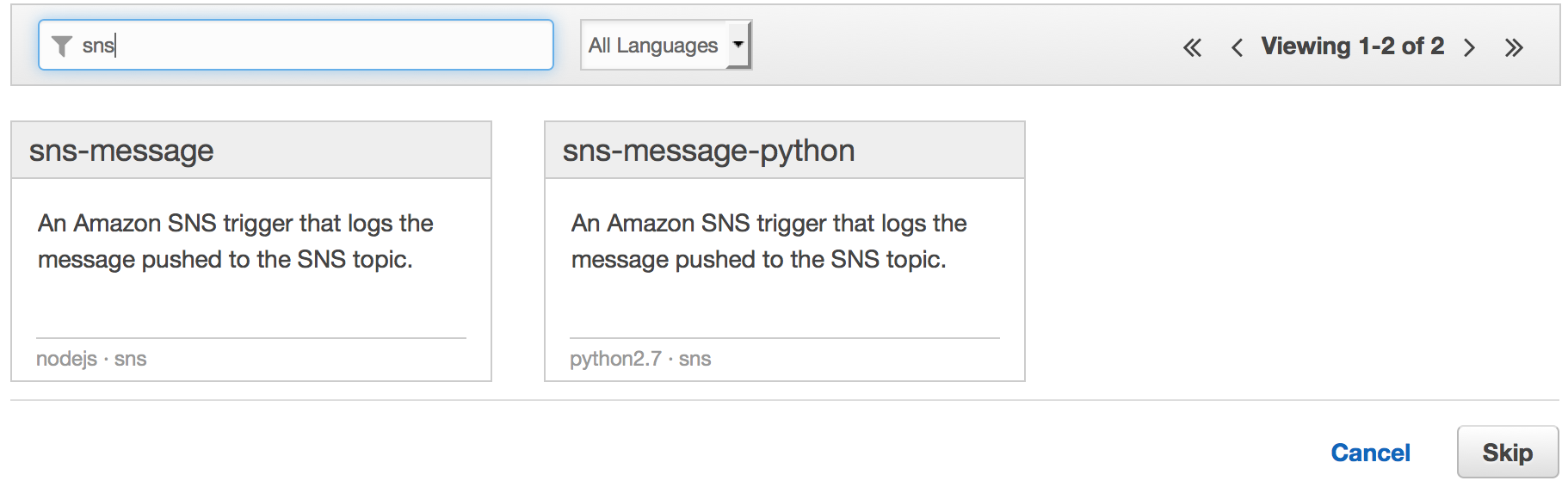
Filter by SNS in the given samples because we want to see SNS functions.
Ensure that you select your SNS as the event source.
Now that we have setup Lambda, SNS, and Github so far, it is time to test the setup.
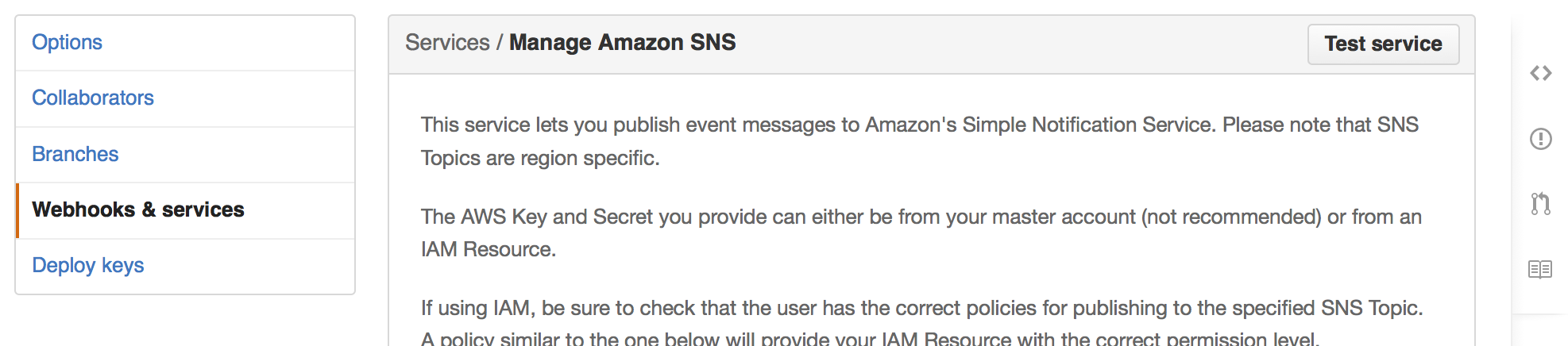
Go to the “Webhooks and Services” under you repo settings and click on “Amazon SNS” that is
viewable at the bottom of that page. You will then be able to test the service.
There’s a button at the top right “Test service”. Once you click it, GitHub will confirm that the message is indeed sent.
Checking AWS
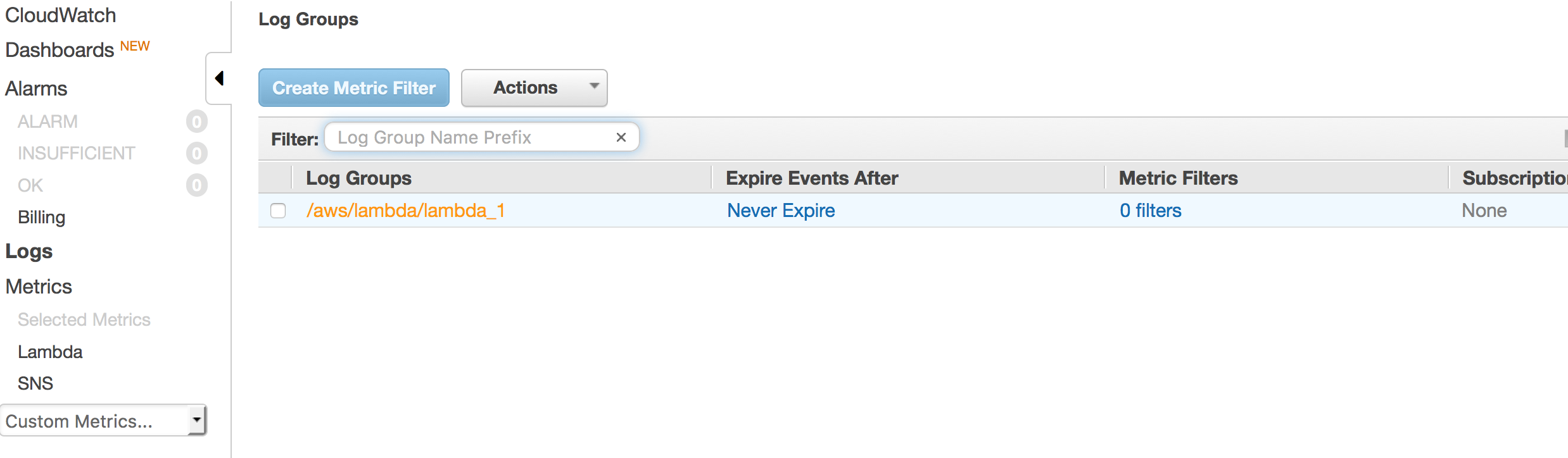
Now that we have been able to send the message, we also need to confirm that the lambda was actually called.
This can be done by looking at CloudWatch logs. Any lambda run will be logged under CloudWatch.
Even normal logging is also available there.
Going to CloudWatch
Checking the lambda logs
Setup API Gateway
After all this is done, we can even create an API along with a public facing URL
where all these services can be called (apart from just GitHub), if you’d like.
So let’s do that.
Create API
Creating an API
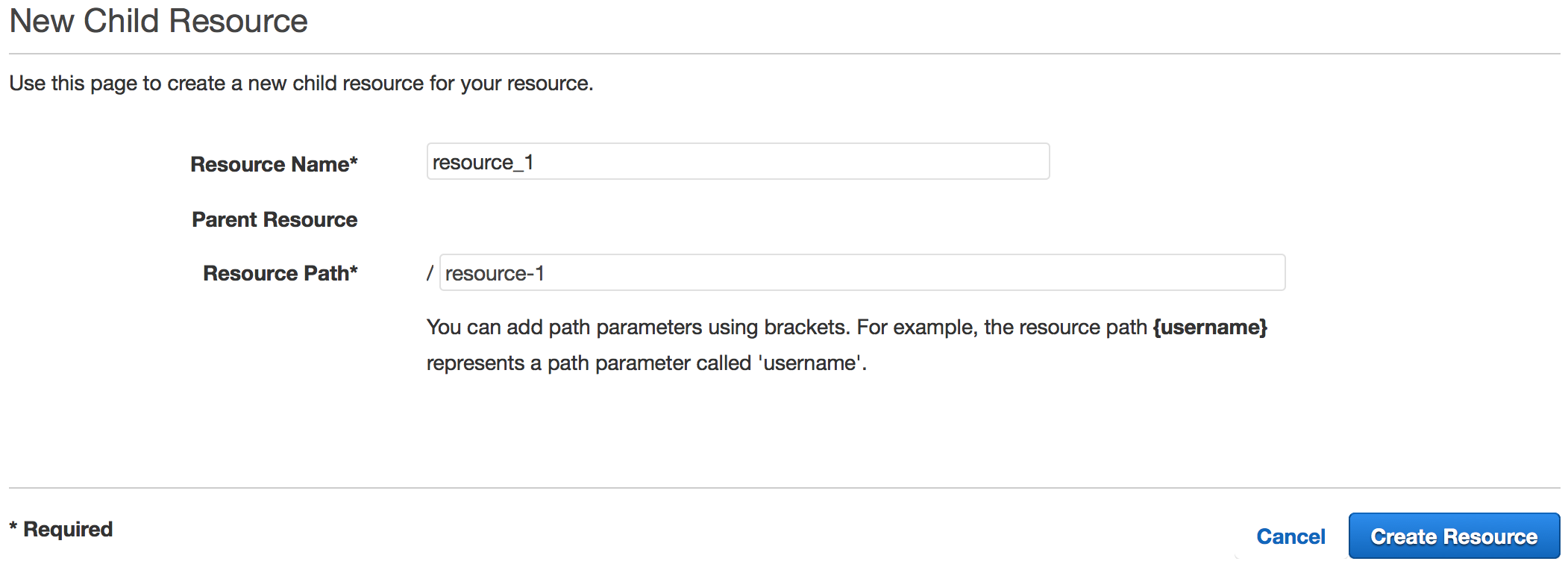
Create Resource
Creating Resource
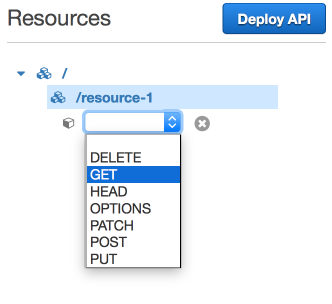
Create Method
Creating Method for GET
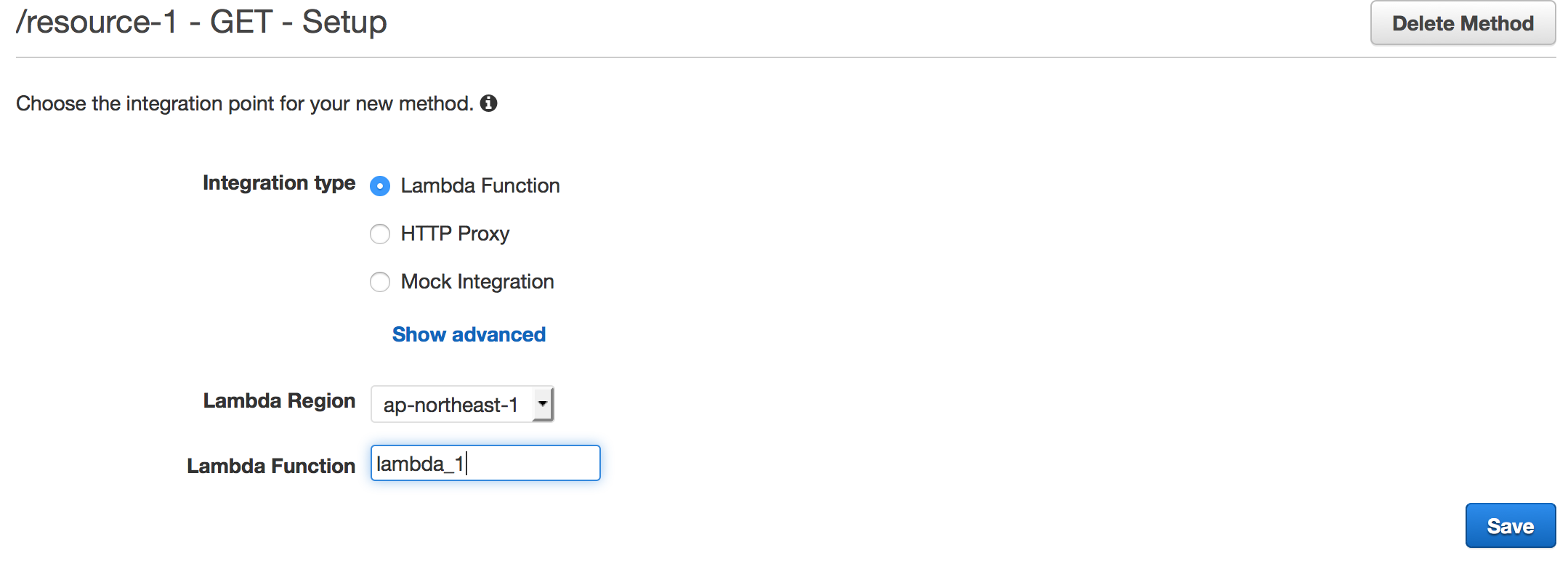
Assign Lambda function to GET
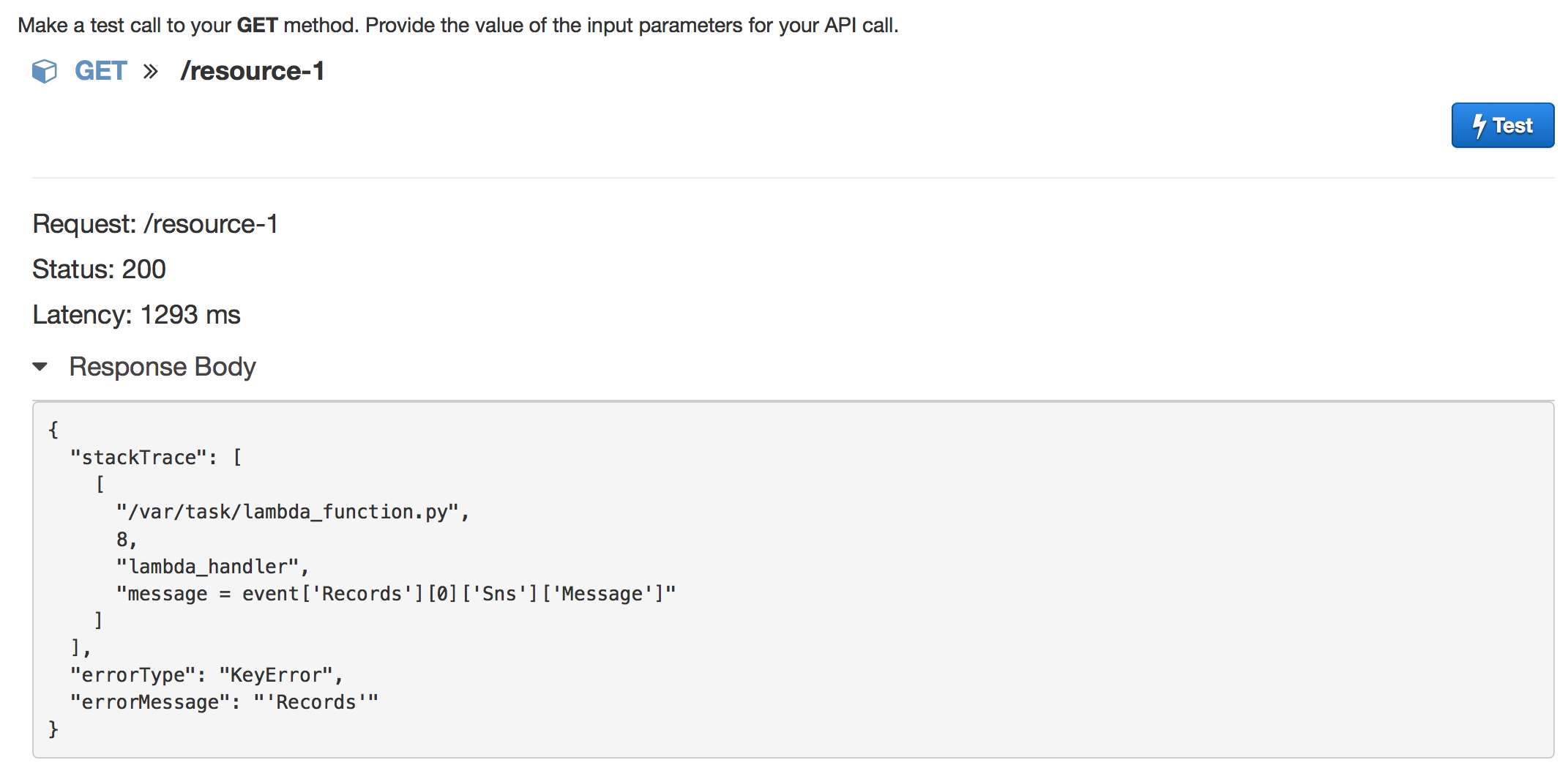
Test your GET Method
Now this API can be tested easily by just calling upon this URL:
{"Functions":[{"CodeSize":317,"FunctionArn":"arn:aws:lambda:ap-northeast-1:XXXXXXXXXXXX:function:lambda_1","MemorySize":128,"Role":"arn:aws:iam::XXXXXXXXXXXX:role/lambda_basic_execution_1","Handler":"lambda_function.lambda_handler","Runtime":"python2.7","CodeSha256":".....","FunctionName":"lambda_1","Timeout":183,"LastModified":"2015-11-15T07:49:28.367+0000","Version":"$LATEST","Description":"An Amazon SNS trigger that logs the message pushed to the SNS topic."},{"CodeSize":316,"FunctionArn":"arn:aws:lambda:ap-northeast-1:XXXXXXXXXXXX:function:lambda_2","MemorySize":128,"Role":"arn:aws:iam::XXXXXXXXXXXX:role/lambda_basic_execution_1","Handler":"lambda_function.lambda_handler","Runtime":"python2.7","CodeSha256":".......","FunctionName":"lambda_2","Timeout":3,"LastModified":"2015-11-14T14:03:00.083+0000","Version":"$LATEST","Description":"An Amazon SNS trigger that logs the message pushed to the SNS topic."}]}
Custom Policy for Lambda Access
Validate Policy
You can either just give “AmazonSNSFullAccess” to the user lambda.s3.1 or add the following Policy
onto User->Permission->Add Inline policy->custom policy->Select->Policy Document
After installing spf13 vim every time I would open a file I had trouble with two things on my mac:
File opening would halt in the middle with the following error : Cannot find word list “en.utf-8.spl” or “en.ascii.spl”
Syntax highlighting also failed thereafter
Here’s what I would see:
$ vim release.sh
Warning: Cannot find word list "en.utf-8.spl" or "en.ascii.spl"
Press ENTER or typecommand to continue
I googled a lot regarding this but didn’t find anything straight forward.
When all options failed I recalled that it is looking for the spell files in a specific folder.
Hence I decided to do a lookup for them:
Let’s take the example of my domain itself abhipandey.com that I want to serve from abhi1010.github.io.
We will need to do it in two steps:
Setup CNAME on github
So that github knows about your domain
Setup A record on AWS Route 53
So that domain can be registered
Change CNAME
If we want to tell github about the domain name, it is rather simple: create a CNAME file with the content being
the name of the domain itself
Do note here that the default redirect of your domain will be the value in your CNAME file.
You don’t really need www. If you do put www.abhipandey.com github will figure out and redirect properly.
The difference is abhipandey.com is a top-level domain (TLD), while www.abhipandey.com is a subdomain.
Essentially:
If your CNAME file contains abhipandey.com, then www.abhipandey.com will redirect to abhipandey.com.
If your CNAME file contains www.abhipandey.com, then abhipandey.com will redirect to www.abhipandey.com.
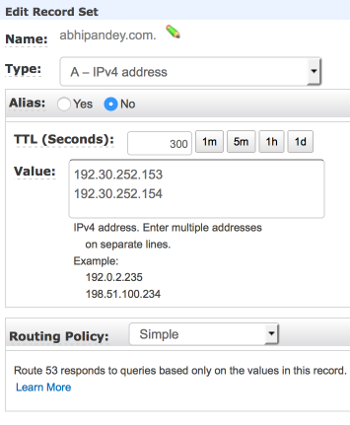
Creating A Record
Setting up A record
Next is to go to Amazon Route 53 console, and create an A record with the following IPs:
192.30.252.153
192.30.252.154
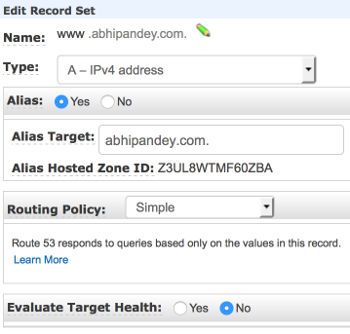
Setup subdomain
Setting up subdomain
If you configure both an apex domain (e.g. abhipandey.com) and a matching www subdomain (e.g. www.abhipandey.com),
GitHub’s servers will automatically create redirects between the two.
You can also also look up GitHub Tips for
configuring an A record with your DNS provider.
Note: If you are not sure of what you are doing here, don’t touch it.
This is all sensitive stuff and a minor mistake can bring down your production.
Sometimes, because of so many deployments happening and sharing volumes between dockers instances, the space runs out on production server.
I found some ways to fix this but the most brutal way to leave the orphaned directories behind forever is to remove them.
Such sadistic directories can be found at /var/lib/docker/vfs/.
We can automate the removal.
First, let’s find the directories that we should not delete.
# These directories are in use
$ docker ps -q | xargs docker inspect | egrep "var.lib.docker.vfs"
Git Mirror from Gitlab to Bitbucket using Gitlab CI
Had to move from BitBucket to Gitlab; which is really great, btw. However, there was one tiny issue here - Gitlab was not supported by Shippable.
As you may know already Shippable is a hosted cloud platform that provides hosted continuous integration.
We use it in our current setup to do a full testing and deployment onto AWS Elastic Beanstalk.
Since we were moving to Gitlab I wanted to continue using Shippable for our prod deployments. Shippable only supports Github or Bitbucket and therein lies the problem.
Gitlab did not work with Circl CI or Travis CI or Shippable or Wercker so I tried using Gitlab CI.
However, there were some issues with it:
Runs the tasks as standalone but are not part of a Docker process
This means Gitlab CI does not work similar to Circl CI or Travis CI or Shippable or Wercker
Sometimes CI takes long to be triggered even though it registers you to be running right after your commit
The terms are a bit different compared to the other cloud based continuous integration sites
Gitlab CI supposedly tries to improve upon other tools but in the process ensures that you need to learn CI again if you want to use them
I tried using the same yaml was Shippable but it was just not working with too many errors being reported and not to mention, having to wait for an hour during the worst period to see results.
Shippable on the other hand, would hand over the console and results within 5 minutes of my commits. Decided to ditch Gitlab CI.
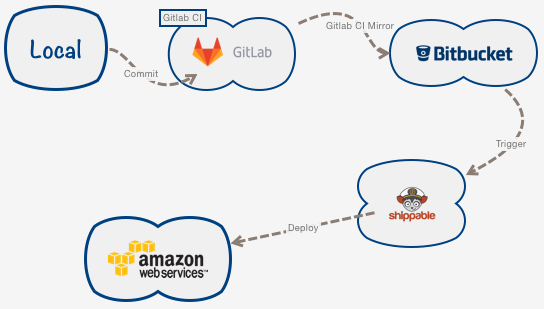
Using Git Mirror
Since Gitlab CI was clearing not working I decided to continue using Shippable. The only issue was, code had to exist in Bitbucket.
For that, I needed a git mirror from Gitlab to Bitbucket. Looking into docs I found this link - http://docs.shippable.com/using_gitlab/.
Other options mentioned setting up configs to add a mirror. For example, look here:
I had a major problem with all the options - every developer had to set it up for this to work on every commit.
I looked into webhooks and triggers on Gitlab but webhooks would have old code (unless I updated the code manually before loading).
Finally, the only way I saw fit to fix this issue was the Gitlab CI itself. I set up a git push as a one-step CI on Gitlab itself.
This would do the following:
A commit on Gitlab leads to CI enabling this git push --mirror through the file .gitlab-ci.yml
When the commit is mirrored on Bitbucket, the webhook there is registered with Shippable which triggers the actual deployment through shippable.yml
In a way Shippable doesn’t need to know anything about Gitlab which is great
Note: Remember to use variables in Gitlab CI to set up your bitbucket username and password.
This had to be done because you can’t have any ssh key from Gitlab to add it to Bitbucket
Recently had an interest in seeing how many LOC were committed to the code base over a particular period of
time. After some tinkering around, mainly to find out the correct format for time ranges, decided to use the following bash script for finding coding stats.
Following sample is to find out lines added or removed during the year 2014.
$ git log --after="2014-1-1" --before="2014-12-31" --pretty=tformat: --numstat
| awk '{ if ( $2 != 0 && $1 != 0 ) print $0 }'| gawk '{ add += $1; subs += $2; loc += $1 - $2 } END { printf "Added lines: %s Removed lines: %s Total # of lines: %s\n", add, subs, loc }'
The result will be as follows:
Added lines: 327505 Removed lines: 243860 Total # of lines: 83645
You will notice in the second line that I am doing the following:
if ( $2 != 0 && $1 != 0 )
This is simply to discard off any commit numbers that were pure addition or deletion (with no corresponding delete or add in the same commit).
It may also remove some numbers that were actually valid commits but mostly it is to protect ourselves against any library or API that we may have added or replaced during that time period.
For time range, you may even use something like --since="1 year ago" and that will also yield similar results.
My blogging experience started with blogspot. It was great until I realized that I needed something that was responsive.
The layout looked nice on 1024x768 but with the new generation of screens it started to look narrow.
I hated the look of the website when it seemed that I was wasting a lot of white space on the web pages.
I moved to wordpress.com to give that a try when they started their responsive themes.
The website looked great after a lot of customization but after writing some posts there,
I realized that I had to micro-manage a lot of styling every time I was writing some new section, like special blocks or tables.
The post writing was fun only for a short while. The enthusiasm died down pretty soon.
Options
I stopped blogging for a while for such reasons. Eventually I heard about Jekyll and was again motivated to try it.
However, since I had also moved from C++ to Python I figured there’s bound to be something that’s gonna be related to Python
so that I can quickly jump in and navigate my way into the code base should there be a need (and who doesn’t find reason to do that?).
Jekyll was ruby based and that was holding me back a bit.
During my research I found out three options:
Jekyll
A lot of mileage but based on ruby
Pelican
During my testing everything was great about it. Even setting up themes was extremely easy. Anything I tried, worked at my first try.
The biggest drawback against pelican and jekyll was that the bigger the number of posts get the longer it takes for compilation to take place
Hugo
Was deemed to have the best build times of 1ms per page
Extremely easy setup with livereload
Lots of other smaller features but just these two items were enough to get me sold on hugo.
livereload is a killer feature as it means you don’t have to keep on rebuilding your site every time you want to view how the contents affect your site.
It was also extremely easy to make theme changes and see them in action, straight away. We will see details of this, later.
Was already using pelican but decided to give hugo a weekend and see it from there. I am glad I did.
Installing hugo
Running it on mac, installation was pretty straightforward using brew
brew install hugo
I wanted to setup Pygments as well for code scripts as well.
I knew that I would be presenting a lot of code on my site and one of my main problems with site like wordpress was that
I had to manage a lot of styling for code sections which was not fun.
So I decided to install Pygments on default python by doing:
pip install Pygments
Exporting wordpress
Since I wanted to move all of my wordpress content into hugo I really needed to export everything from wordpress.
I found this link on wordpress to export all of the contents out into xml file.
The next task was to convert the xml file into markdown files so that hugo could use them. However, I had already converted
some of my files earlier while working on pelican. Once I started using them I realized that my contents were not looking as expecting when I was iterating through
various themes. Sometimes things looked okay and other times not. I figured it must be something to do with how markdown was laid down from the xml file because
the tags and categories were missing. I double checked the wordpress xml file but it contained the tags and categories that I was looking for.
It was time to start digging again.
I came across exitwp which needed a bit of setup, but I was willing to give it a try.
Here’s what I did:
git clone https://github.com/thomasf/exitwp
cd exitwp
cp wordpress.2015-08-23.xml wordpress-xml/
# install dependencies
pip install --upgrade -r pip_requirements.txt
# Run cmd with path to xml (optional if you have only one file)
exitwp.py wordpress-xml/wordpress.2015-08-23.xml
This creates a folder build/jekyll/OLD_WORDPRESS_URL/ with the contents inside it. Here’s my sample
Now that we have made some markdown files, we just want to see how it looks like on default hugo setup.
hugo documentation mentions says that all you need to do is call it with your input files.
The idea would be to start a new folder, copy your markdowns there. Here’s what we need:
Setup
config.toml file for all the configuration that will be used by hugo to build the site
Markdown to be put in content folder
themes/{THEME_NAME} folder container the actual theme in {THEME_NAME} folder
Other minor things to note here:
Output html files are put in public folder.
It is usually a good idea to keep separate folders for testing and production otherwise you may inadvertently commit your dev test pages (thanks to livereload
I have seen hugo to complain quite a lot if you have your static files within themes/{THEME}/static folder
You can get around it in two ways.
Create a symbolic link from within your blogging folder by calling ln -s themes/hyde-x/static static
Copy the static folder as is in to the main folder location, as is by calling cp -r themes/hyde-x/static/ ./. However, do this only if you don’t intend to mkae any changes
mkdir my_blog
cd my_blog
mkdir content
cp -r /PATH_TO/exitwp/build/jekyll/codersdigest.wordpress.com/* ./content/
Your config file could be as follows. Do note that I am also trying to build a menu for myself on the sidebar for better tracking.
It can be found under [[menu.
baseurl="your_github_url"languageCode="en-us"title="title"contentdir="content"layoutdir="layouts"publishdir="public"theme="hyde-x"pygmentsstyle="native"pygmentsuseclasses=false[author]name="your name"[permalinks]# Change the permalink format for the 'post' content type.# This defines how your folder is structuredpost="/:year/:month/:title/"[taxonomies]# I wanted to use tags and categoriescategory="categories"tag="tags"[[menu.main]]name="Posts"pre="<i class='fa fa-heart'></i>"weight=-110identifier="posts"url="/post/"[[menu.main]]name="Tags"pre="<i class='fa fa-road'></i>"weight=-109url="/tags/"[[menu.main]]name="Categories"pre="<i class='fa fa-road'></i>"weight=-108url="/categories/"
Run hugo
Now that we have setup the contents, themes
$ hugo server
0 draft content
0 future content
42 pages created
0 paginator pages created
18 tags created
6 categories created
in 53 ms
Serving pages from /Users/your_username/code/githubs/_tmp/_del/public
Web Server is available at http://127.0.0.1:1313/
Press Ctrl+C to stop
Final look
You’re done. How does it look?!
Your sidebar
Going further
This is only the beginning. There are still a few loose ends to tie up.
What about code highlighting? Would you like more changes?
hyde-x also provides it’s own version of highlighting through css files. You can use params to control that
I wasn’t happy with the code highlights as well the default layout the themes were providing. I created my own adaptation of hyde-x called hyde-a
Some changes I made were:
Tags and Categories didn’t have their own proper listing or single templates
Every time you clicked on a tag/category, the list of all articles related to that term was also not shown properly
Post listing only included title and date. I was looking for related tag and category for each post
Now that we have created the blog, how about hosting it?
We have use a free service like GitHub Pages
Once we commit your html pages (the output) onto github on a different repo it will show up directly on github.io as well.
There are some concepts that you want to know. Learn some at [octopress])(http://octopress.org/docs/deploying/github/).
Create your own repo using the following logic:
You must use the username.github.io naming scheme.
Content from the master branch will be used to build and publish your GitHub Pages site.
Automating your blog generation
Now that our blog is generated, we need to automate the process of creating the html from the markdown.
If we have to commit to two repo - for markdown as well html pages, I feel like is too much of work.
I did some work with shippable and started automatically creating the html pages through it.
I have created another article about it while taking Elastic Beanstalk as the subject. The same applies for hugo though. You can find it here:
Shippable will pick it up from there. It will download the theme and create the html files.
It will also commit to the GitHub Pages for you and the site will be live automatically!
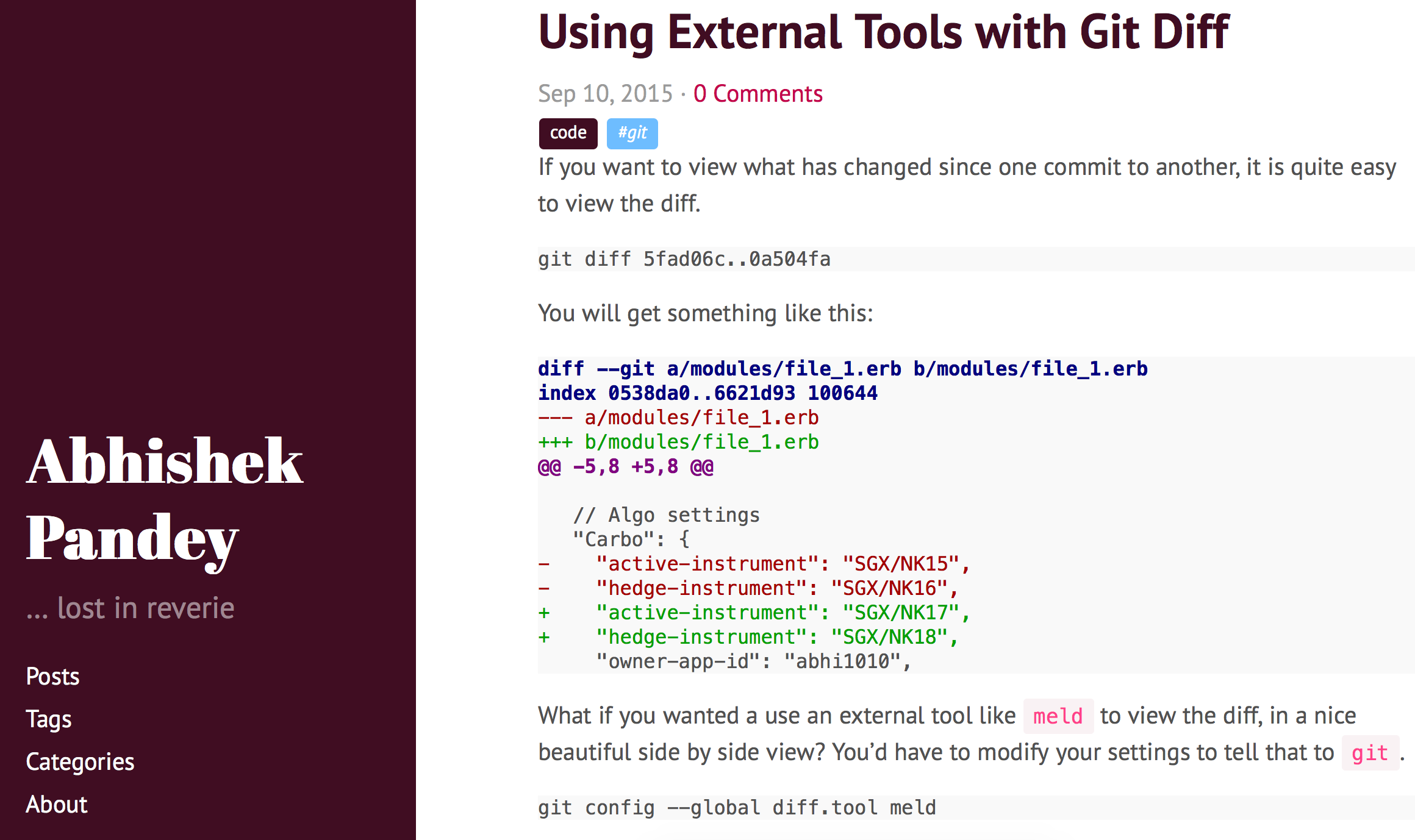
What if you wanted a use an external tool like meld to view the diff, in a nice beautiful side by side view? You’d have to modify your settings to tell that to git.